Oftentimes it is difficult and messy to copy-and-paste rows of data from PDF files to a spreadsheet like Excel. This online tool allows you to extract one more more tables of data into a Microsoft Excel spreadsheet simply using an online tool.
How to Use
- Upload a PDF file containing a table of data.
- Enter the page number(s).
- Select a focal table by dragging a rectangle around all of the data you want to include.
- A window will then appear containing your data. Inspect the data to make sure it looks correct. If data is missing, you may have to slightly expand your selection.
- Download as Excel or CSV.
- Now you can work with your data as text file or a spreadsheet rather than a PDF!
(You can open the downloaded file in Microsoft Excel or the free LibreOffice Calc)
Note: This tool only works on text-based PDFs, not scanned documents.
Having trouble?
- The extractor said “Sorry, your PDF file is image-based” — what does that mean? Your PDF does not have any embedded text. It might have been scanned from paper. Tabula is not able to extract any data from image-based PDFs. You can try OCRing the PDF with a tool like Adobe Acrobat Pro (paid), Tesseract, PDFSandwich (Mac/Linux, free) or Lime OCR (Windows, free) and then trying this tool again.
- Some columns of my table are combined. What can I do? The extractor sometimes uses “streams” of whitespace to recreate your table’s structure. If headers span multiple columns, they’re probably causing a problem. Try excluding them from your selection (or selecting them separately).
- Some columns of my table are combined. And the headers aren’t the problem! What else can I do? The extractor has two extraction methods. It tries to guess which one is right for document, but it’s wrong sometimes. Try selecting the other (of “stream” and “lattice”), on the left in extraction mode, to see if that fixes the problem.
- The PDF to Excel Tool helps, but my extracted data isn’t in the layout I want! How can I fix that? The tool tries to recreate the table structure of the original document. You can think of this as a data extraction tool rather than a data transformation tool. If you want to clean and transform your exported CSV or Excel Workbook, a spreadsheet program like Excel or Google Sheets might be a good place to start.
Technical Notes about this PDF to Excel Converter
This SuperTool does table recognition and parsing. This pursuit concerns the recognition and extraction of tables from a human-readable format (usually PDF) into a machine-comprehensible format (like Excel).
The work involves several parts, each with its own algorithm. The flow chart below is similar to what works with SuperTool’s extraction engine.
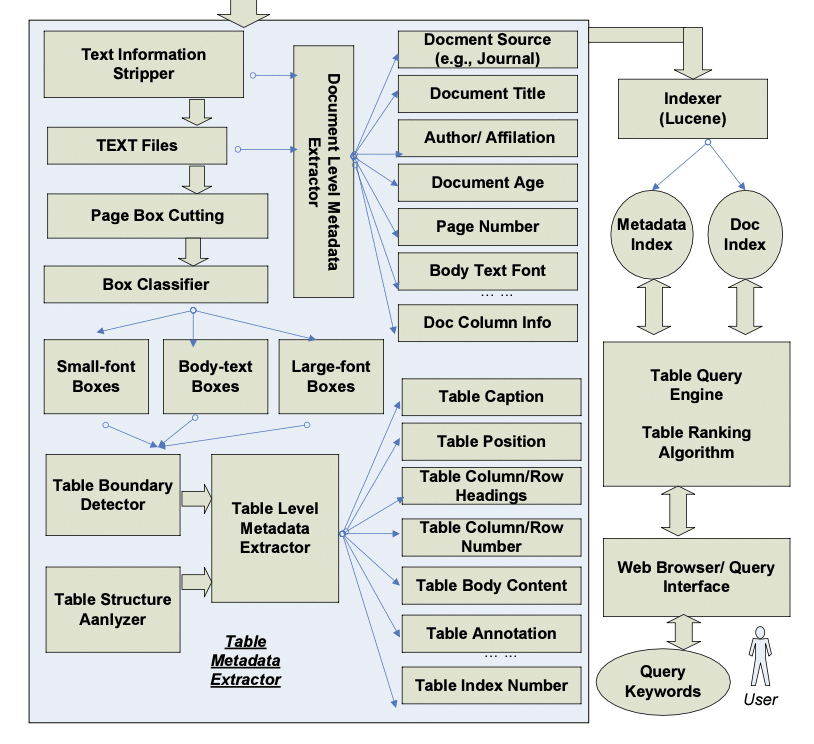
- Identify the table boundary and the table structure including the headers, columns, and rows of the table. One difficult issue is classifying cells into “data cells” versus “header cells”.
Table Header Detection
The primary difficulty in accurately extracting machine-readable data from PDF tables is the diversity of table structures. There are tables with and without headers, nested tables (whose certain cells are small tables themselves), and even tables that include bar charts in them alongside numeric or textual data. SuperTool’s algorithms use several rubrics to classify PDF data into headers, columns, and rows including prioritizing the first few rows, looking at class and data type differences, and more.
Types of PDF Tables
Most tables are either 1 dimensional or 2 dimensional. A table with 1 dimension has either column or row headers. A table with 2 dimensions has both. Those kind of tables make up the overwhelming majority of table types. Tables can have column headers that look like merged cells and/or headers across multiple rows.
The layout of a table can be encoded in text or image file (i.e., a PDF), while the logical structure (what are rows, data types, relationships between cells) of a PDF is not included in a PDF.
Check out a brief demo of how to convert a PDF to Excel.
Awesome Other Tool: Insert a signature onto a pdf and make it look printed and scanned.